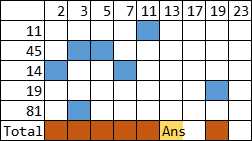
因为我们学校里的在线评测系统没有办法屏蔽 #pragma GCC optimize 预处理指令,因此出现了如下的状况:
因此,今天我决定从根源上禁止这些行为。
正好前两天看到洛谷上屏蔽手动 O2 O3 Ofast 的方式,于是今天自己就来试着修改 GCC 的源代码,并计划手动编译并上线测试。
需求整理
- 魔改编译器禁止手动优化;
- 编译器版本之间可以分离,不予系统自带的编译器冲突;
GCC 9+GCC 12。
准备工作
如果你也是某个 OJ 的运维/管理,直接在服务器上构建源代码会更好,但是注意资源占用。
如果你只是自用,那么无所谓。
但是前提是一定要在一个 Linux 环境下操作。(我也只写了 Linux (Ubuntu) 的记录啥的)
正式安装
安装需要的库
文档是按照最新的正式版 GCC 12 写的,向下兼容。
根据 Prerequisites for GCC 所说,总结下来,最省心的情况(我的情况)需要如下条件:
- 通常是系统自带的
- Ubuntu >= 20.04 (当然可以不是这个发行版,但
CentOS算了) - 一个 POSIX Shell,但不包括
zsh。 - GCC >= 9.4
- Python 3
- ssh, git 等
- Ubuntu >= 20.04 (当然可以不是这个发行版,但
- 需要手动构建安装的
安装依赖库的过程相对简单。步骤总价下来无外乎以下几点:
- 下载依赖库源码包
- 上传源码包到服务器
- 解压源码包
cd到源码包解压到的目录- 执行:
./configure && make && sudo make install
一定要从上往下依次安装。
配置
现在假定你的源代码存放在 src 目录下。在 src 的上级菜单新建文件夹 obj。
1 | |
在 obj 目录下执行 configure 指令。
比方说,我的指令是:
1 | |
(32 位机器大概不适用)
--with-pkgversion 指 g++ --version 时显示的版本号(下面括号里的内容),具体如下:
1 | |
--host=x86_64-pc-linux-gnu 是说目标平台的架构。
更多配置项目参见 Installing GCC: Configuration 。
构建
本过程大约需要 $0.6~4$ 小时。期间服务器的资源会爆满。建议使用 screen 在后台运行。
构建很简单,在 obj 文件夹下执行 make 即可。或者说,机子够强,可以并行构建,执行 make -j <线程数> 即可。
然后就是艰难的等待。我个人建议在机子终端面前守着,防止意外错误。
我遇到了一个错误,libgsl.so.23 没找到。这个 issue 解决得还不错,就是修改 ld 寻找 so 文件的目录。
1 | |
若构建中断,可以从断点重新开始构建。make 还是比较智能的。
安装
要是不出意外的话,构建将会在很长一段时间之后结束。此时可以执行 make install。
但!是!我要版本隔离!
make DESTDIR=<目标目录> install 可以让 GCC 安装在指定目录。比如:
1 | |
目录不存在的话会自动新建。
安装好的 GCC 的 bin 在 <DESTDIR>/usr/local/bin/。
总结
等死我了。最后 make install 的可执行文件对于每一台机子都不一样,不可直接一直。烦死了。白编译三个小时。
版权信息 / Copyrights
头图:Pixiv PID 106462140 使用未经授权 侵权联系我删除
Header image of this article: Pixiv PID 106462140; Unauthorized use, infringement contact me to delete.